

گوگل چگونه کار می کند؟
رباتهای گوگل (Spider Google Bot) با دنبال کردن لینک های جدید 24 ساعته شروع به دیدن میکنند (یک روزی از سایتهای معتبر دنیا شروع کردهاند مثل نیویورک تایمز) و محتوای لینکها را آنالیز میکنند (آنالیز video, title, picture, content و…)، موضوع و کیفیت را تشخیص میدهند سپس محتوا را دانلود میکنند (Indexing) اگر مرتبط باشد در نتایج نمایش میدهند (Serving)، این رباتها برای دیدن اولیه سایتها و دیدن دوباره نیاز به سرور دارند.
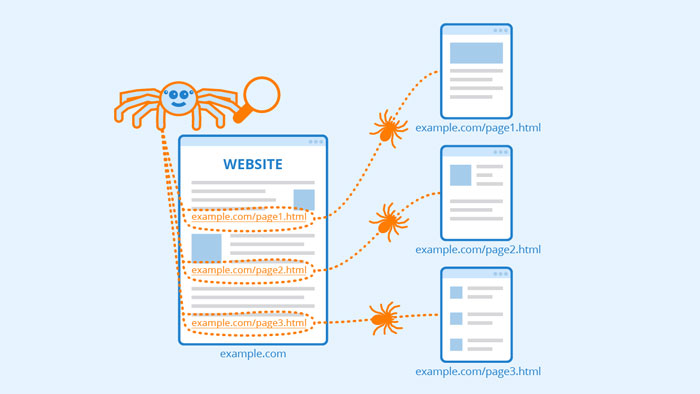
معماری جستجوی گوگل
موتور جستجوی گوگل از اجزا یا ربات های مختلف تشکیل شده است:
- Crawler
- Indexer
- Ranking
در مرحله اول خزنده ها (crawler) تمامی لینک های موجود در صفحات سایت را جمع آوری میکنند، بعد از آن Indexerها پارامترهای مهم را از صفحات استخراج میکنند و در پایگاه داده گوگل ذخیره میکنند. پایگاه داده گوگل از دو Index تشکیل شده است که شامل Mobile و Desktop است. در سمت دیگر، کاربری یک کوئری را در Interface گوگل سرچ میکند. بعد از آن یکی از اجزا گوگل به نام Query Parser عبارت جستجو شده را به یک عبارت قابل فهم توسط موتورهای جستجو تبدیل میکند و بر این اساس یک سری نتایج مرتبط در ایندکس گوگل شناسایی میشوند.
حال الگوریتم های گوگل، Ranking را بر اساس فاکتورهای مهم گوگل که بیشتر از 200 مورد اعلام شده است به هر کدام از این نتایج یک امتیاز میدهند و بر اساس این امتیاز ها نتایج Sort و به کاربر نمایش داده میشود.
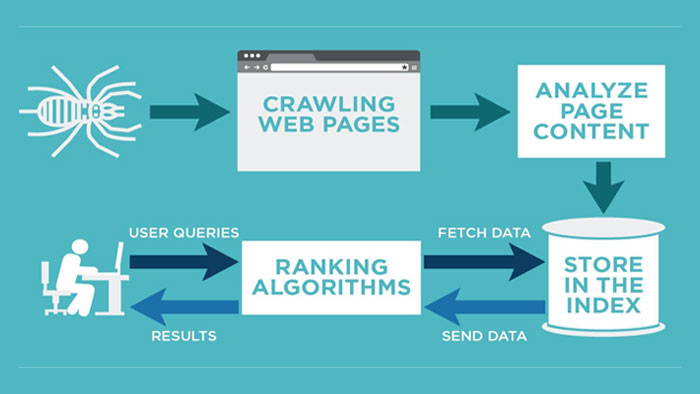
نکات کرالینگ (Crawling)
Crawling دو مرحله دارد:
- URL discovery: در URL discovery دیتابیس یا سبدی از URL با پیدا کردن لینکهای جدید، ایجاد میکند.
- Crawling: محتوا دانلود میشود.
روشهای دیسکاوری:
- دریافت لینک از صفحاتی که قبلا دیسکاور شدن
- ایجاد سرچ کنسول و ثبت سایت مپ
- راههای احتمالی دیگر مثل مرورگر کروم که برای گوگل است وقتی آدرس را تایپ یا سرچ میکنید، استفاده میکند.
اگر یک URL دیسکاور شود اما کرال نشود ممکن است کاربر دسترسی به آن صفحه را بسته و یا نیاز به لاگین دارد.
ربات قبل ورود و دیسکاور، وضعیت ورود به یک صفحه را چک میکند مثلا تگ Noindex دارد یا در Robots.txt محدود شده است یا نه! اگر محدود باشد کرال نمیکند.
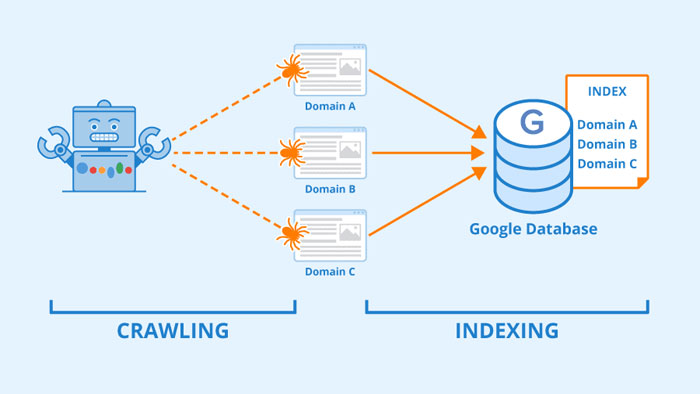
نکات ایندکسینگ (Indexing)
داپلیکیت بودن صفحه و محتوای آن در همین محله توسط گوگل برسی میشود اگر کپی باشد ادامه نمیدهد.
عوامل ایندکس نشدن:
- کیفیت پایین محتوا
- تگ نو ایندکس
- دیزاین نامناسب
- مسدود کردن از طریق Robots.txt
- کنونیکال اشتباه

نکات سروینگ یا همان رنکینگ (Serving Search results)
وقتی یک کوئری سرچ میکنیم صدها عامل در رتبه بندی تاثیر دارد از جمله مکان ما (با ویپیان خاموش سرچ میکنیم چون با ویپیان IP کشور دیگری میشود و نتایج عوض میشود.)، زبان، دیوایس (نتایج موبایل و دسکتاپ متفاوت است)، History مرورگر و سرچ (وقتی زیاد وارد یک سایت میشویم رتبههای بهتری در موبایل ما میگیرد)
با ctrl+shift+N در حالت Incognito سرچ میکنیم هیستوری قبل تاثیر داده نمیشود و چیزی در هیستوری کروم ذخیره نمیشود.
مفهوم Relevancy و بقیه رنکینگ فاکتورها در این مرحله مهم میشوند. Relevancy کلمه سرچ شده با صفحه کم یا زیاد است؟ اگر زیاد بود نمایش میدهد.

دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.